By Rachel M. Shaffer and Annie Doubleday
Disclaimer: The views expressed in this post are those of the authors and not their employers.
“What does the AQI really mean?!”
That was the essence of many questions from friends and family trying to navigate personal decision-making and risk calculations during the recent (and ongoing) unprecedented smoke episode affecting the east coast and midwest of the United States.
As environmental epidemiologists with expertise in air pollution, we have both thought about this question in relation to our research as well as on a personal level from living through multiple difficult wildfire seasons in the Pacific Northwest.
Introduction to the AQI
The Air Quality Index (AQI) is, just as the name implies, an index to report air quality and is used as a public health tool for communicating risk due to air pollution.
Below is the basic version of the AQI table, with color coded categories and levels of concern corresponding to each numerical range of AQI values.
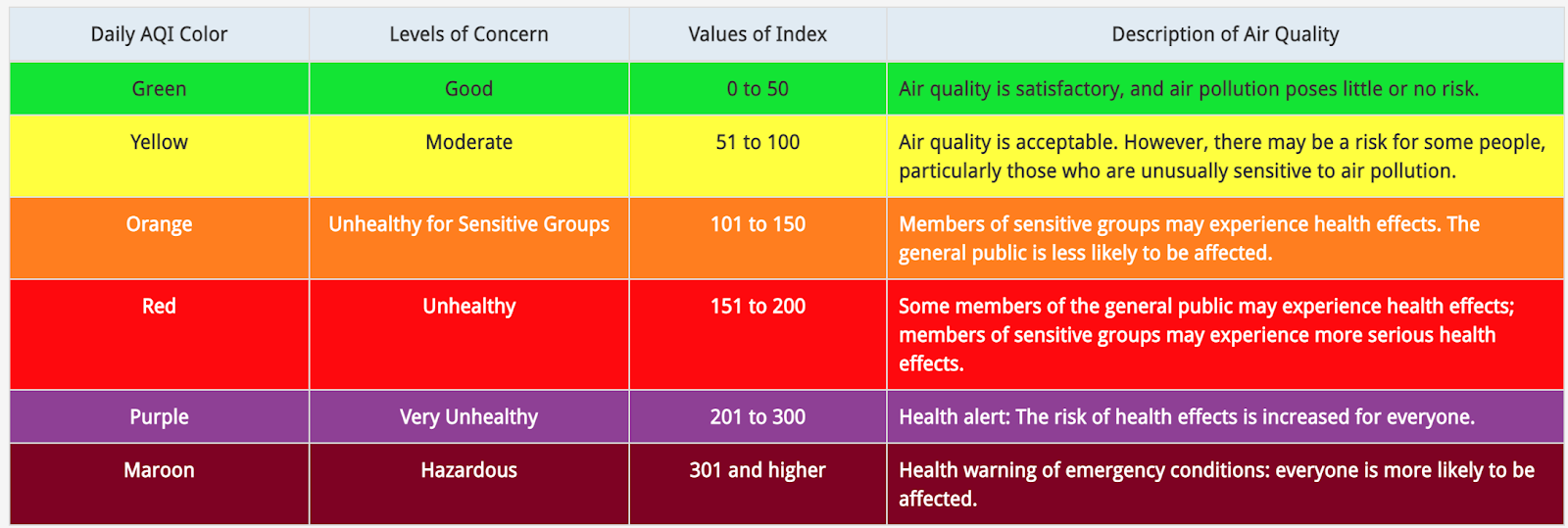
https://www.airnow.gov/aqi/aqi-basics/
EPA actually develops a specific AQI table for five of the “criteria pollutants” regulated under the Clean Air Act: ozone, particulate matter (PM2.5 & PM10), carbon monoxide, sulfur dioxide, and nitrogen dioxide (see pp. 4-5 in this technical assistance document for a master AQI table for all of these pollutants). The overall AQI for a given day is determined by the pollutant with the highest concentration (usually PM2.5 or ozone).
The Meaning Behind the AQI
But how are these generic index values (e.g., 0-50, 51-100) linked to air pollutant levels?
Let’s explore this question in the context of the AQI for PM2.5, the most relevant index to consider for wildfire smoke.
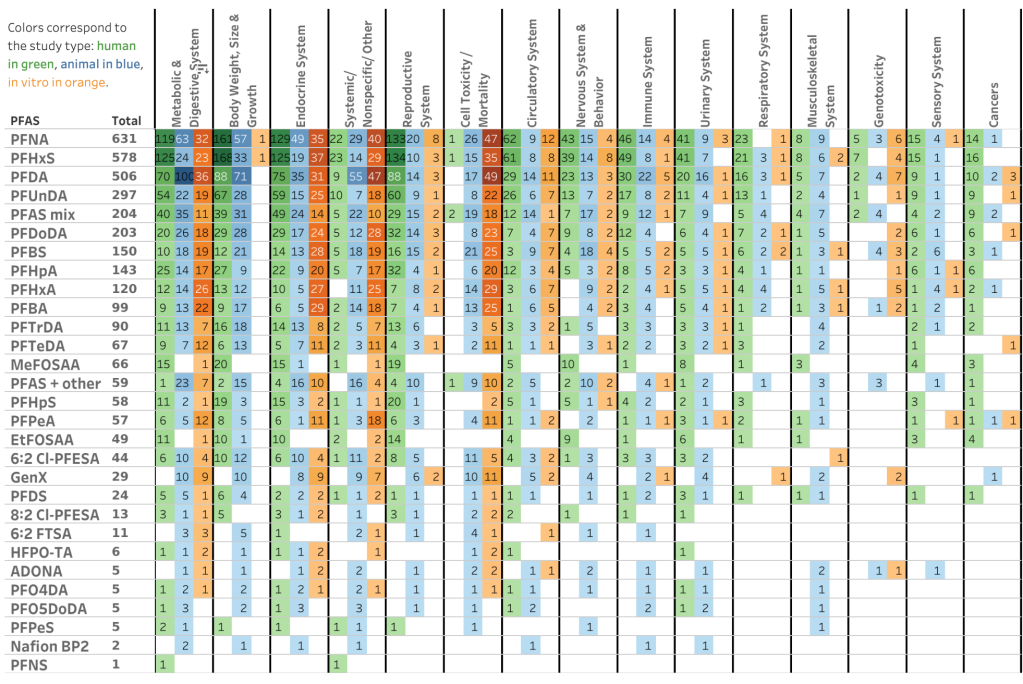
| AQI Category | Value of Index | 24-hr PM2.5 (µg/m3) | Rationale for Upper Bound |
| Good | 0-50 | 0-12.0 | Current annual average National Ambient Air Quality Standard (NAAQS) for PM2.5 |
| Moderate | 51-100 | 12.1-35.4 | Current 24-hr average NAAQS for PM2.5 |
| Unhealthy for Sensitive Groups | 101-150 | 35.5-55.4 | “…the health effects evidence indicates that the level of 55 µg/m3 …is appropriate to use” (2013 Federal Register Notice) |
| Unhealthy | 151-200 | 55.5-150.4 | Linear extrapolation approach, assuming that increased PM2.5 concentrations are associated with greater proportions of the population affected |
| Very Unhealthy | 201-300 | 150.5-250.4 | |
| Hazardous | >300 | >250.4 |
The AQI cut-point of 50 (defining the upper end of the “Good” category) corresponds to an average PM2.5 concentration of 12.0 µg/m3 over a 24-hr period, the current National Ambient Air Quality Standard (NAAQS) for annual average exposure to PM2.5. (EPA has a structured process to revisit the NAAQS (approximately every 5 years), and these associated AQI cut-points get updated each time the standards are updated.)
The AQI cut-point of 100 (defining the upper end of the “Moderate” category) corresponds to 35 µg/m3, the current 24-hr average NAAQS for PM2.5.
As for the next category? Well, here’s where it gets hazier. The 2013 Federal Register notice (published for the last AQI updates) does not provide clear information on how the 55 µg/m3 cutpoint (the upper end of the “Unhealthy for Sensitive Groups” category) was determined. The explanation is simply that “the health effects evidence indicates that the level of 55 µg/m3… is appropriate to use.”
And what about the cut-points for the higher categories? These are also not linked to any specific health effects evidence but instead determined by a linear extrapolation approach, with the assumption that increased PM2.5 concentrations are associated with greater proportions of the population affected.
The bottom line: the lower levels of the AQI are closely linked to national air quality standards and associated scientific research, but there is more uncertainty about the evidence used to set the upper levels.
Be cautious with the AQI
The AQI is the best approach that we currently have for quickly communicating information about air pollution risk to the general public. However, to be an informed “user” of this information (in essence, to calibrate your individual actions in relation to your own risk), it is important to understand the uncertainties and limitations in the index.
- Differing composition of wildfire smoke PM2.5 vs. ambient PM2.5
The research used to set the NAAQS for PM2.5 – and correspondingly the AQI, as described above – is primarily based on ambient PM2.5 (usually from traffic, urban, or industrial sources), which has been the focus of extensive research for the past several decades. However, there is growing evidence that wildfire-associated PM2.5 is different from industrial/traffic-related PM2.5. For example, research to date indicates that wildfire-associated PM2.5 contains more toxic metals and is overall potentially more toxic to human health. This suggests that using an AQI based on ambient PM2.5 to understand risk from wildfire PM2.5 could lead to some uncertainties in estimating risks.
- Uncertainties about the relevant exposure period
An important consideration in thinking about how an environmental exposure, like wildfire smoke, affects human health is to figure out which “exposure metric” is most relevant. For example, is it:
- peak exposure (e.g., a one-time, very high exposure that pushes your body over a threshold to initiate a cascade of adversity)?
- average exposure?
- cumulative exposure (i.e., over a lifetime)?
The AQI is based on 24-hr average pollutant concentrations, so the implicit assumption is that average daily exposure is a good metric for understanding/predicting health impacts. Most studies on wildfire smoke exposure have focused on 24-hour exposure or cumulative exposure over 2-7 days. We don’t yet have a complete picture on how peak exposure or cumulative exposure over a lifetime might affect health outcomes. So, if you are making decisions based on the AQI, remember that this index is focused on short term exposures and short term outcomes.
- A single pollutant index in a multi-pollutant world
Each individual pollutant’s AQI only considers potential health effects linked to that single pollutant. And each day’s overall AQI is only based on the highest overall single pollutant AQI. For example, if the AQIs for ozone, PM2.5, and carbon monoxide are 126, 102, and 90, respectively, the overall AQI for the day will be 126. In the case of wildfire smoke, the AQI is based on PM2.5 alone rather than the associated toxic gasses. This ignores the potential additive or synergistic effects of exposure to multiple air pollutants at high levels over a single 24-hr period.
- No clear “safe” level of exposure
The more we learn about PM2.5, the more we realize that there might not be a clear “safe” level of exposure. This idea was described in the 2013 FR notice: “the epidemiological evidence upon which these [divisions] are based provides no evidence of discernible thresholds, below which effects do not occur in either sensitive groups or in the general population.”
The AQI paints a slightly different picture. For example, the index indicates that this 24-hr average PM2.5 of 35-55 µg/m3 is only concerning for “sensitive groups.” Based on this guidance, the general population is not likely to make behavior changes in this range. However, evidence indicates population-wide impacts at and below these exposure ranges. In fact, an analysis of New York hospitalization data indicated that most excess hospital admissions occurred when the AQI was <100 (35-55 µg/m3).
Of course, getting PM2.5 down to zero is an infeasible goal from a regulatory perspective, and public health guidance is based on a combination of science and practicality. But with the growing understanding of PM2.5’s acute or chronic effects on almost every organ system at even very low levels of exposure, we recommend taking steps to reduce exposure even at lower levels of the AQI.
So, what does this all mean?
The AQI, like any other public health index or set of recommendations, has to distill complex information down to relatively simple forms and be able to make general recommendations despite real uncertainties and nuances (we saw this with public health messaging around COVID-19, also).
No index will be complete or perfect. But to be able to use them effectively/appropriately, it is important to understand some of their details and uncertainties (as we’ve described above).
In the case of wildfire smoke pollution, the AQI provides a good starting point to guide individual actions. However, it is important to listen to your body, pay attention to any symptoms, and consider reducing personal exposure to wildfire smoke even if the AQI category doesn’t officially suggest modifying behavior. Similarly, given the uncertainties regarding particulate composition, potential chronic effects from repeated exposure, mixture effects, and effects from low level exposure, we suggest interpreting the index cautiously. In other words, taking steps to reduce exposure to wildfire smoke is always better!
In the coming years, we hope that emerging research on wildfire smoke can inform updates to the index to better guide appropriate individual actions. Given the growing risk of fires in a changing climate, we will all need to learn how to live with – and protect ourselves – from wildfire smoke.